Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
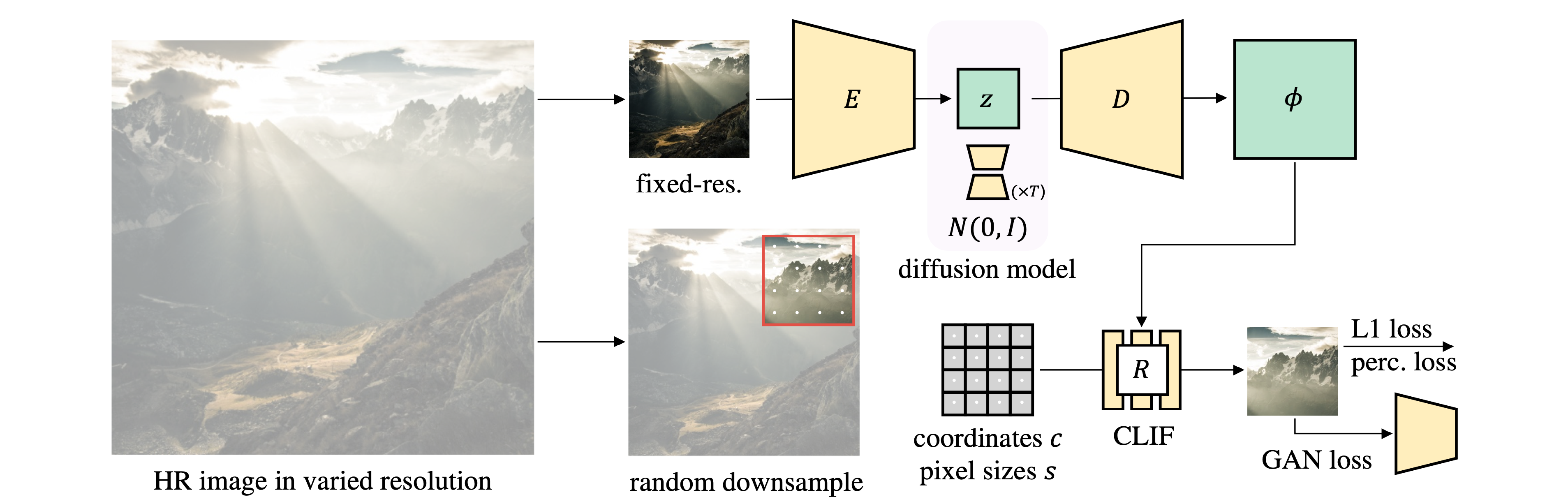
Given a training image at an arbitrary resolution, we first downsample it to a fixed resolution and pass it into the encoder \(E\) to get a latent representation \(z\). A decoder \(D\) then takes \(z\) as input and produces a feature map \(\phi\) that drives a neural field renderer \(R\), which can render images by querying with the appropriate grid of pixel coordinates \(c\) and pixel sizes \(s\). The autoencoder is trained on crops from a randomly downsampled image ground truth, generating image crops at the corresponding coordinates. At test time, a diffusion model generates a latent representation \(z\), which is then decoded and used to render a high-resolution image.
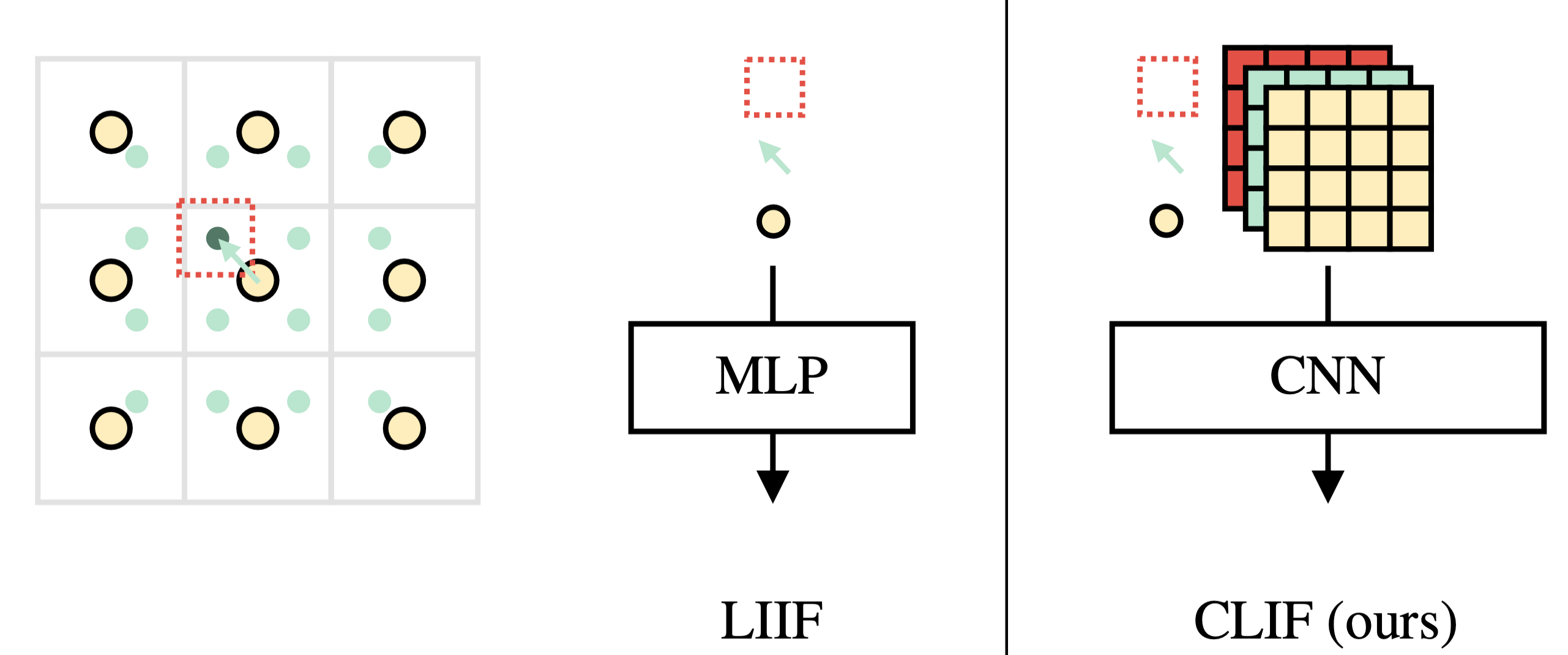
Convolutional Local Image Function (CLIF): Given a feature map \(\phi\) (yellow dots), for each query point \(x\) (green dot), we fetch the nearest feature vector, along with the relative coordinates and the pixel size. The grid of query information is then passed into a convolutional network (right) that renders an RGB grid. Different than the pointwise function LIIF, CLIF has a higher generation capacity and is learned to be still scale-consistent.






Diffusion generates a 64×64 latent as the image neural field and renders at 2048×2048 output resolution (with 256×256 patches).


We observe that even without an explicit consistency objective, CLIF is trained to be scale-consistent. The content aligns when rendered at different resolutions.





We finetune Stable Diffusion with the CLIF render to output at 2048×2048 resolution.

We can solve for a high-resolution image that satisfies multi-scale conditions, defined as square regions and a text prompt (left). For this, we render the corresponding regions at 224×224 and pass it to a pre-trained CLIP model operating at fixed-resolution, and maximize the CLIP similarity to the corresponding text prompt. This enables layout-to-image generation without extra task-specific training. We show generated solutions on the right.
Note that without image neural field, a fixed-resolution diffusion model needs to decode the whole region at full resolution (e.g. 1000×1000 "cloud" region in a 2048×2048 canvas) before passing it as 224×224 input to CLIP, which would have very intensive computation and memory cost.
@inproceedings{chen2024image,
title={Image Neural Field Diffusion Models},
author={Chen, Yinbo and Wang, Oliver and Zhang, Richard and Shechtman, Eli and Wang, Xiaolong and Gharbi, Michael},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8007--8017},
year={2024}
}