Motivating from gradient-based meta-learning
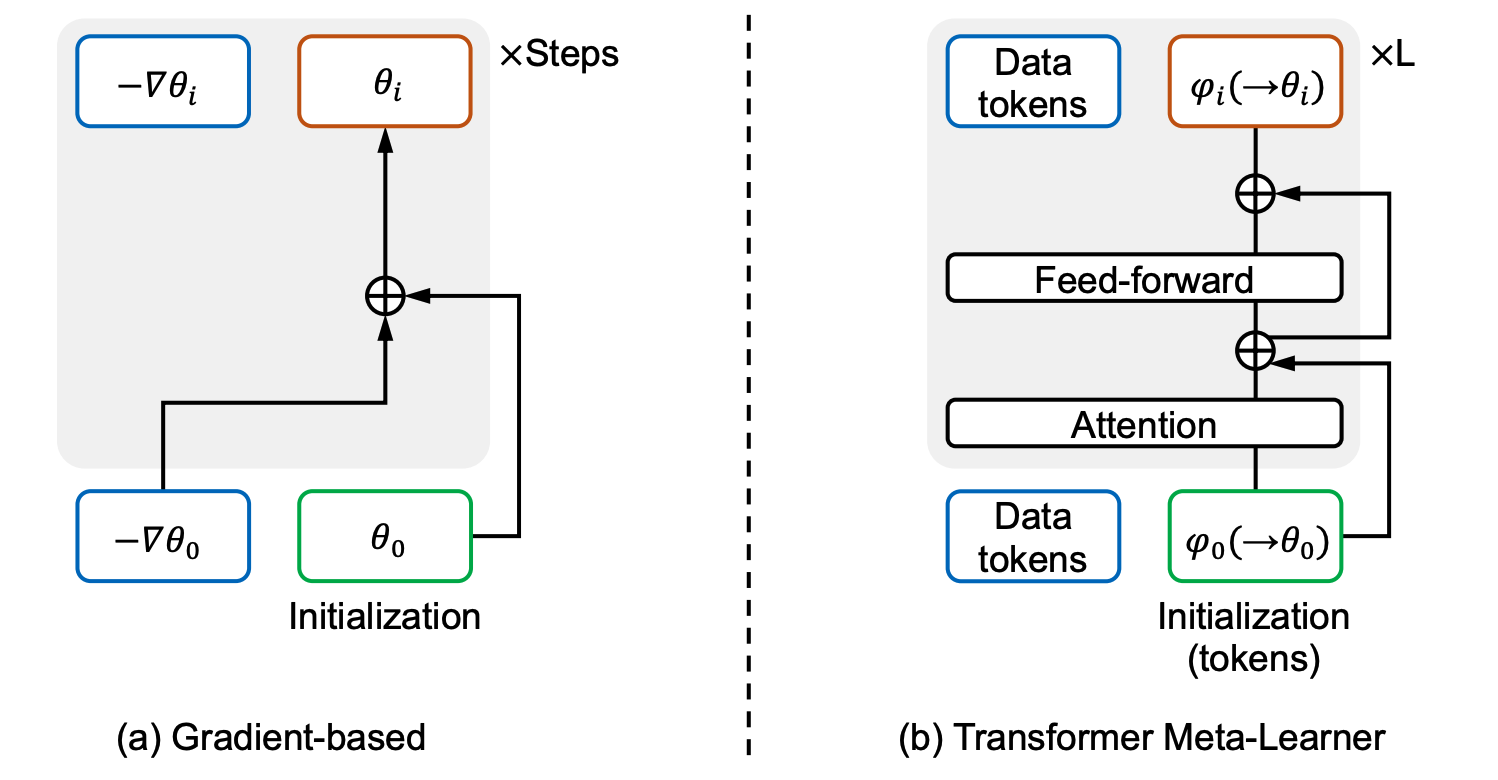
The Transformer architecture can naturally parameterize a learnable initialization and step-dependent learnable update rules as a meta-learner. The residual link in the Transformer meta-learner shares a similar formulation as subtracting the gradients in gradient descent for updating the weights.
Image Regression

(left in each pair is the generated MLP)
View Synthesis
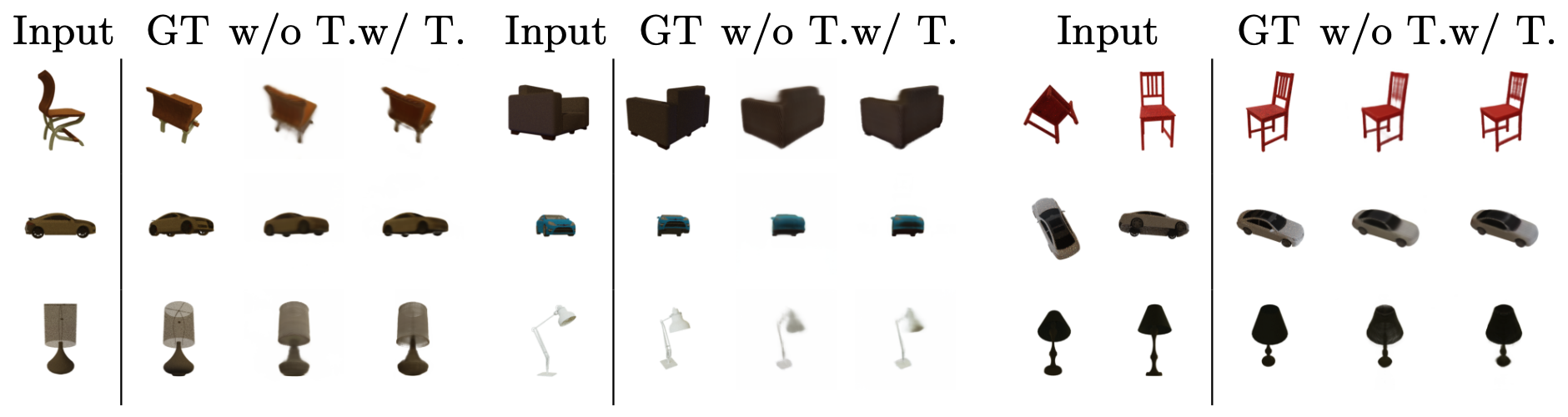
(w/ T. denotes with additional 100 gradient steps to fit the input views)